2026-04-21.不摸鱼的独立开发者日报(第339期)
📰 资讯
闭源AI正在偷走你的数据金矿
当客户使用现成的闭源模型时,最可悲的是他们没有利用自己多年甚至几十年积累的数据。
Mistral首席科学家Guiam在最新一期Lin Space访谈中说出这句话时,演播室里安静了几秒钟。
窗外的巴黎街道车水马龙,屏幕上滚动着各家大模型最新的参数数字和跑分成绩。人们习惯了在这些数字之间比较高低,习惯了打开浏览器调用一个API,输入问题,等待答案。
很少有人低头看看自己服务器里那些沉睡的文件。
那些从公司成立第一天就开始记录的客户对话,那些一代又一代工程师写下的技术文档,那些无数次产品迭代留下的日志,那些只有在这个行业摸爬滚打多年才能获得的经验和教训。
它们以字节的形式存在于硬盘的某个角落,有些已经积满了数字的灰尘。
这些数据不会出现在公开互联网上。
不会出现在Common Crawl的爬虫结果里,不会出现在维基百科的词条中,不会出现在任何一个大模型的训练数据集里。
它们只属于你。
它们记录着你的客户喜欢什么,讨厌什么,在什么环节会犹豫,在什么时刻会下单。它们记录着你的产品哪里容易出问题,哪里可以做得更好。它们记录着这个行业里所有公开场合不会有人说的潜规则和常识。
当你把所有问题都抛给一个通用模型时,这些数据依然在那里沉睡。
你得到的答案,和你的竞争对手得到的答案,没有任何区别。
同一个问题,输入同一个API,返回同一个结果。
Mistral的团队见过太多这样的客户。他们带着自己的问题找到Mistral,说通用模型在他们的领域表现不好。然后Mistral的工程师拿过他们的数据,在一个3B参数的小模型上跑一遍微调。
结果往往超出所有人的预期。
一个在医疗行业深耕了二十年的公司,用自己积累的病历数据微调了一个模型,在诊断准确率上超过了所有通用大模型。
一个汽车制造企业,用自己的生产线数据训练了一个模型,把缺陷检测的准确率提升了十几个百分点。
一个金融机构,用自己的交易记录训练了一个模型,把风险评估的速度提高了几十倍。
这些模型的参数规模,连GPT-4的百分之一都不到。
它们不需要理解莎士比亚的十四行诗,不需要解高等数学题,不需要写代码。它们只需要做好一件事:理解你的业务。
它们运行在你自己的服务器上,运行在你自己的私有云里。数据不会离开你的公司,不会经过任何第三方的服务器。
你不用再担心数据泄露,不用再担心API突然涨价,不用再担心某一天早上醒来,发现自己依赖的服务被关停了。
Mistral在GTC上发布了Forge平台。这个平台把他们自己内部用来训练模型的工具,原封不动地交给了客户。
同样的数据处理管道,同样的训练代码,同样的微调工具。那些Mistral的科学家每天都在使用的东西,现在任何一个公司都可以用。
他们的工程师会走进客户的公司,和客户的团队一起工作。一起整理数据,一起标注样本,一起调试模型,一起解决实际业务中遇到的问题。
有时候是为了让模型更好地识别某个行业的专业术语。有时候是为了让模型适应某个特定的声学环境。有时候是为了让模型支持某个只有几百万人使用的小语种。
这些都是通用大模型永远不会做好的事情。
因为通用大模型要服务于全世界所有人。它只能取平均值,只能给你一个大多数情况下都能用的答案。
它永远不会为了你一个公司,去调整自己的权重。
这次Mistral发布的Voxal TTS模型,同样只有3B参数。它支持九种语言,推理速度比市面上大多数同类模型都快,成本只有它们的几分之一。
他们没有用一个巨大的通用模型来做语音生成。他们做了一个专门的小模型,只做这一件事。
就像他们之前发布的语音识别模型,就像他们发布的OCR模型。
很多人都在谈论全模态大模型,谈论一个模型解决所有问题。但Mistral走了一条相反的路。
他们相信,对于大多数具体的问题,一个小而专的模型,比一个大而全的模型,要好得多。也便宜得多。
这次访谈中,他们聊了很多技术细节。聊了自回归流匹配架构,聊了神经音频编解码器,聊了长上下文建模。
但最打动人的,还是Guiam反复提到的那句话。
关于数据。
关于那些属于你自己的数据。
很多公司花了几百万,几千万,甚至几个亿去买闭源API的服务。却不愿意花十分之一的钱,去挖掘自己已经拥有的数据。
他们把自己最宝贵的资产,锁在了硬盘里。然后去租别人的资产来用。
未来的某一天,当所有公司都在用同一个通用大模型的时候,真正的竞争优势会来自哪里?
不会来自于谁能更好地调用同一个API。
会来自于谁拥有别人没有的数据。
会来自于谁能把自己的数据,变成自己的模型。
会来自于谁能把自己几十年积累的经验和智慧,沉淀在数字的世界里。
演播室的灯光暗了下来。访谈结束了。
窗外的天已经黑了。巴黎的夜晚灯火通明。无数的服务器在城市的各个角落运行着,处理着无数的数据。
其中有一些数据,正在等待着被唤醒。

🖥️ 软件
回声日语
回声日语是一款结合日漫学习日语单词的App,适合对日漫感兴趣且有一定日语基础的用户。
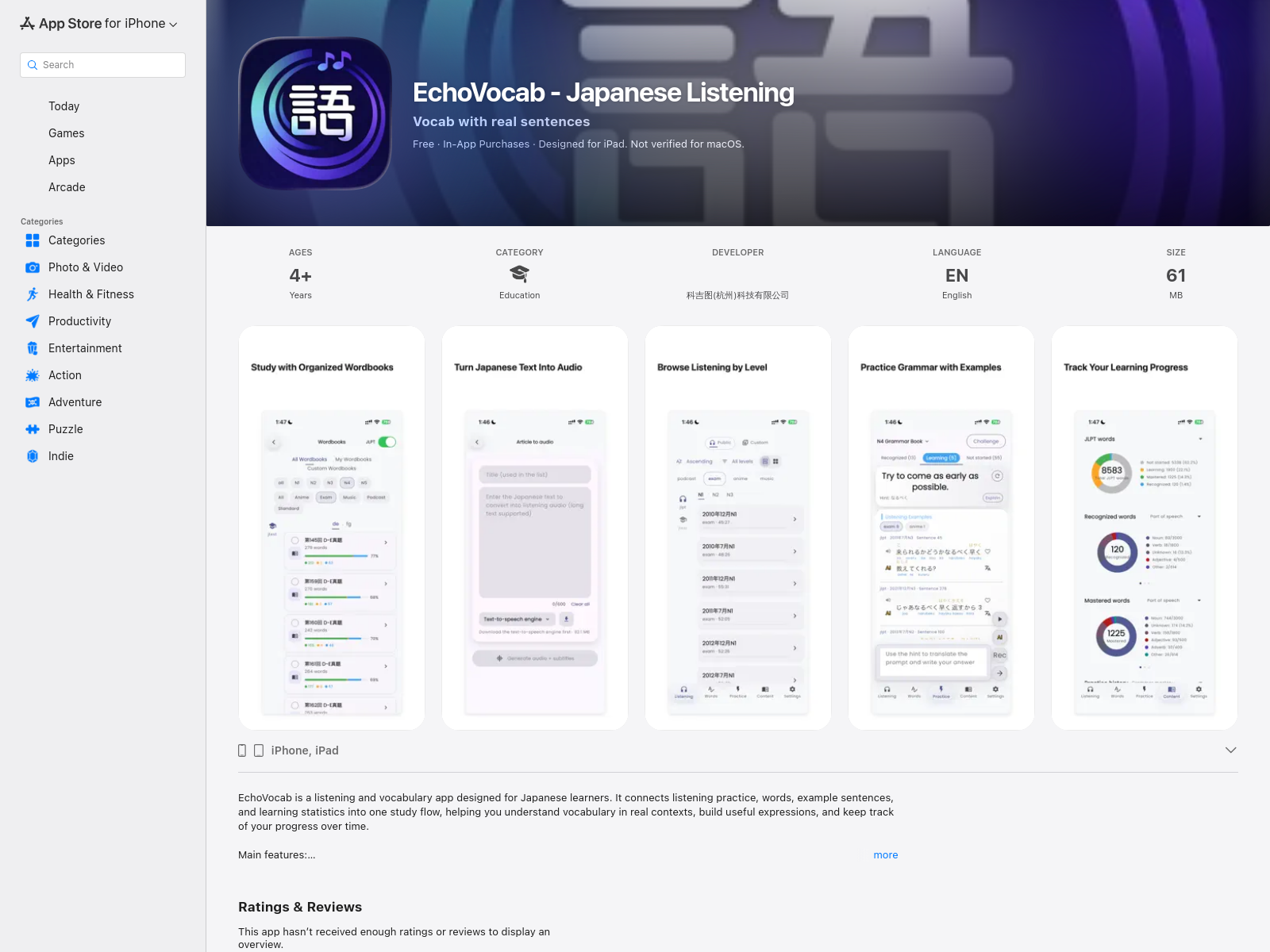
Knowledge Raven
Knowledge Raven是一款基于MCP协议的知识管理工具,支持跨AI平台智能检索文档,可上传文件并实现多模型协同搜索。
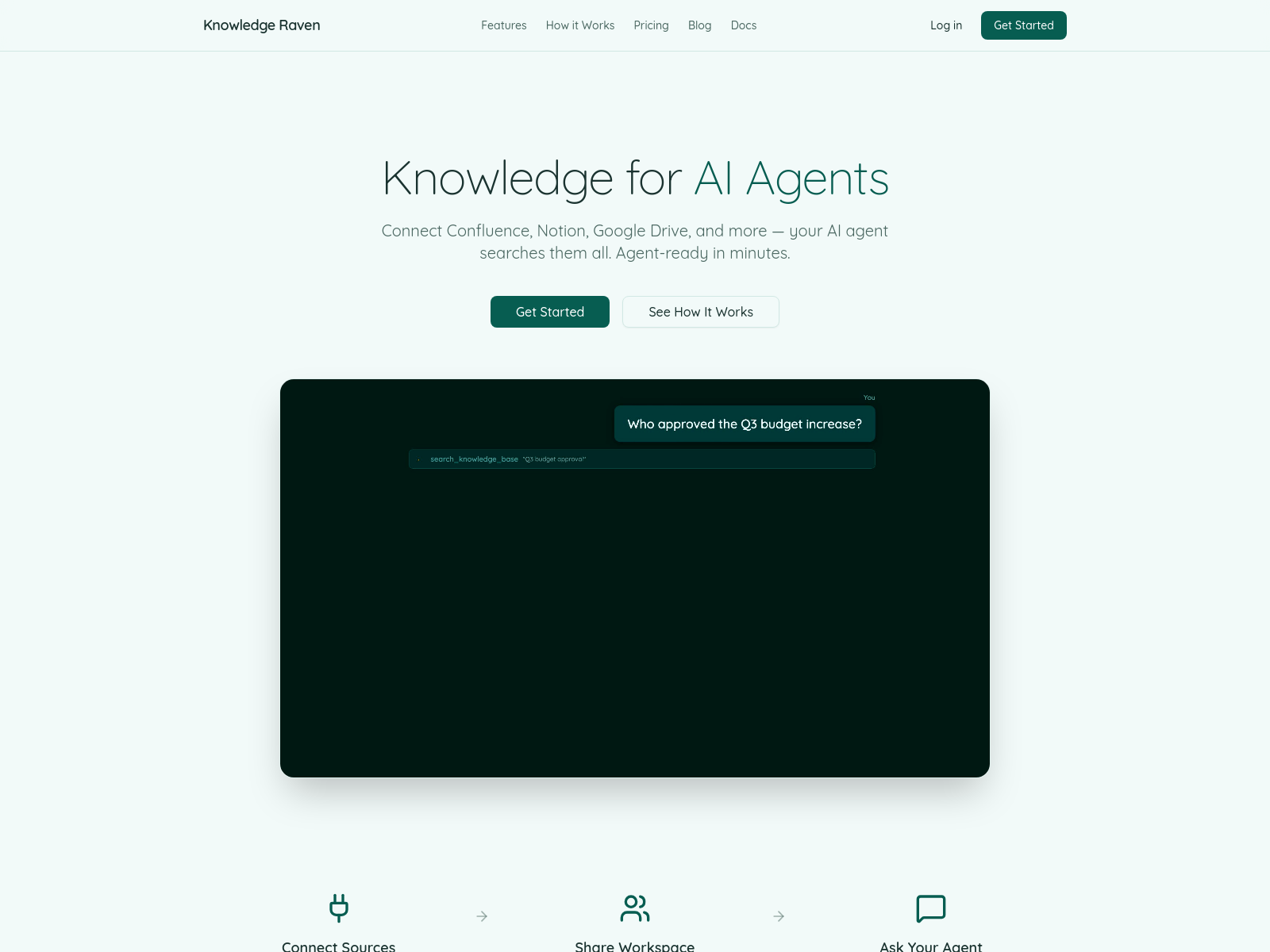
Tubbr
Tubbr是一款帮助YouTube和TikTok创作者通过关键词生成脚本、AI图像与视频的AI工具,支持低成本自动化内容生产。
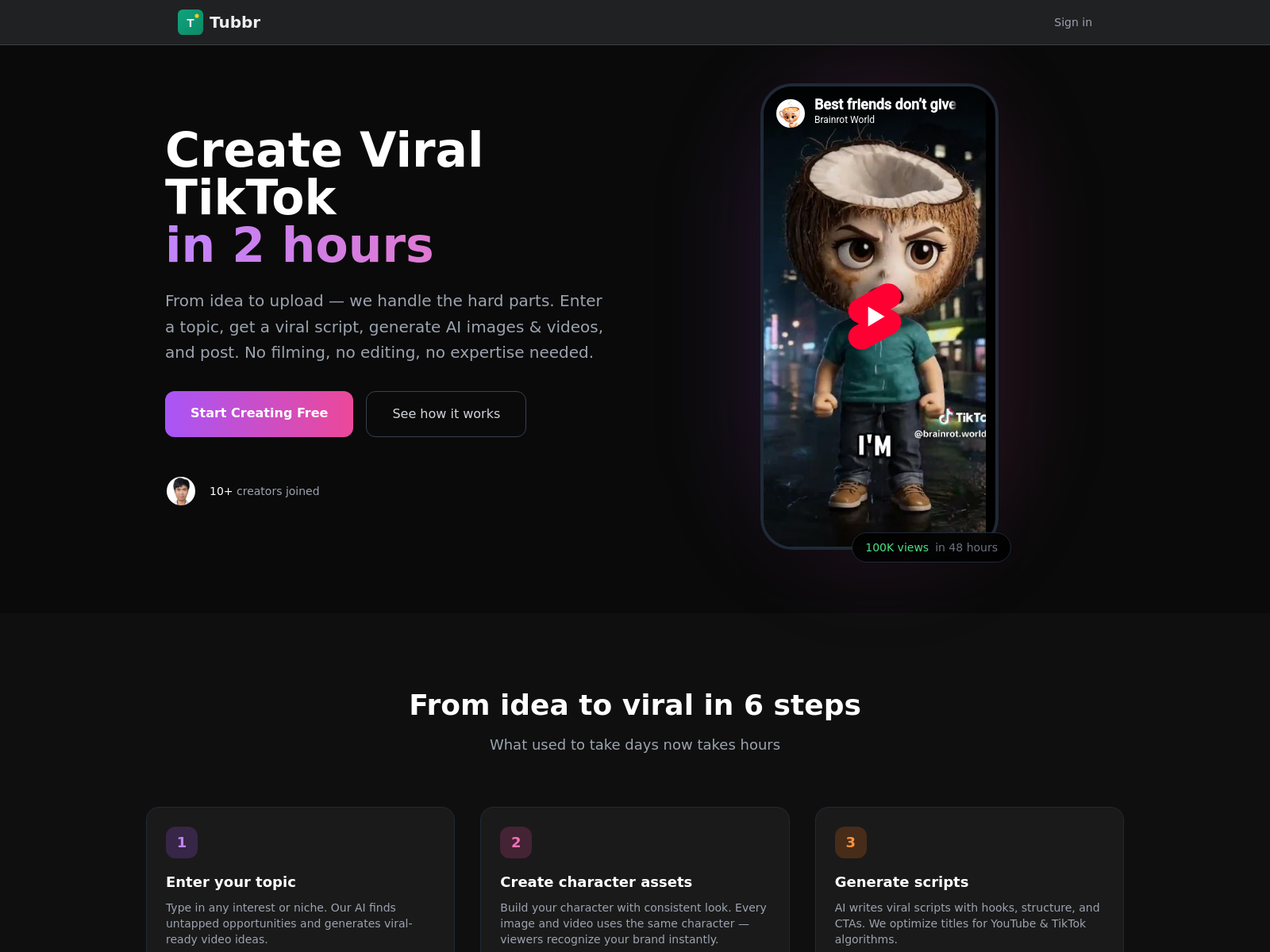
Prompt Vault
Prompt Vault是一款基于Astro与IndexedDB的零后端提示词管理工具,支持本地存储、离线使用与隐私保护。
YNTA
YNTA是一款专为个人教练设计的远程训练管理软件,支持二维码实时连接、AI生成训练计划及语音记录。
markd-essay-ai
markd-essay-ai是一款为英国A-level学生提供多科目论文AI批改与反馈的工具,支持考试大纲并生成模拟题自动批改。
StackMap
StackMap是一款开源CLI工具,可从Terraform、CloudFormation、SAM或实时AWS账户生成可本地编辑的架构图,支持多账户扫描与交互式可视化。
AI Subtitle Studio
AI Subtitle Studio是一款在浏览器中运行的AI字幕视频编辑器,可分析语调自动为每个词语应用不同样式,支持一键增强与逐词富文本编辑。
🌐 网站
GuessTopia
GuessTopia是一款由独立开发者打造的每日地理谜题游戏,通过气候、语言、人口等属性进行逻辑推理猜国家或首都。
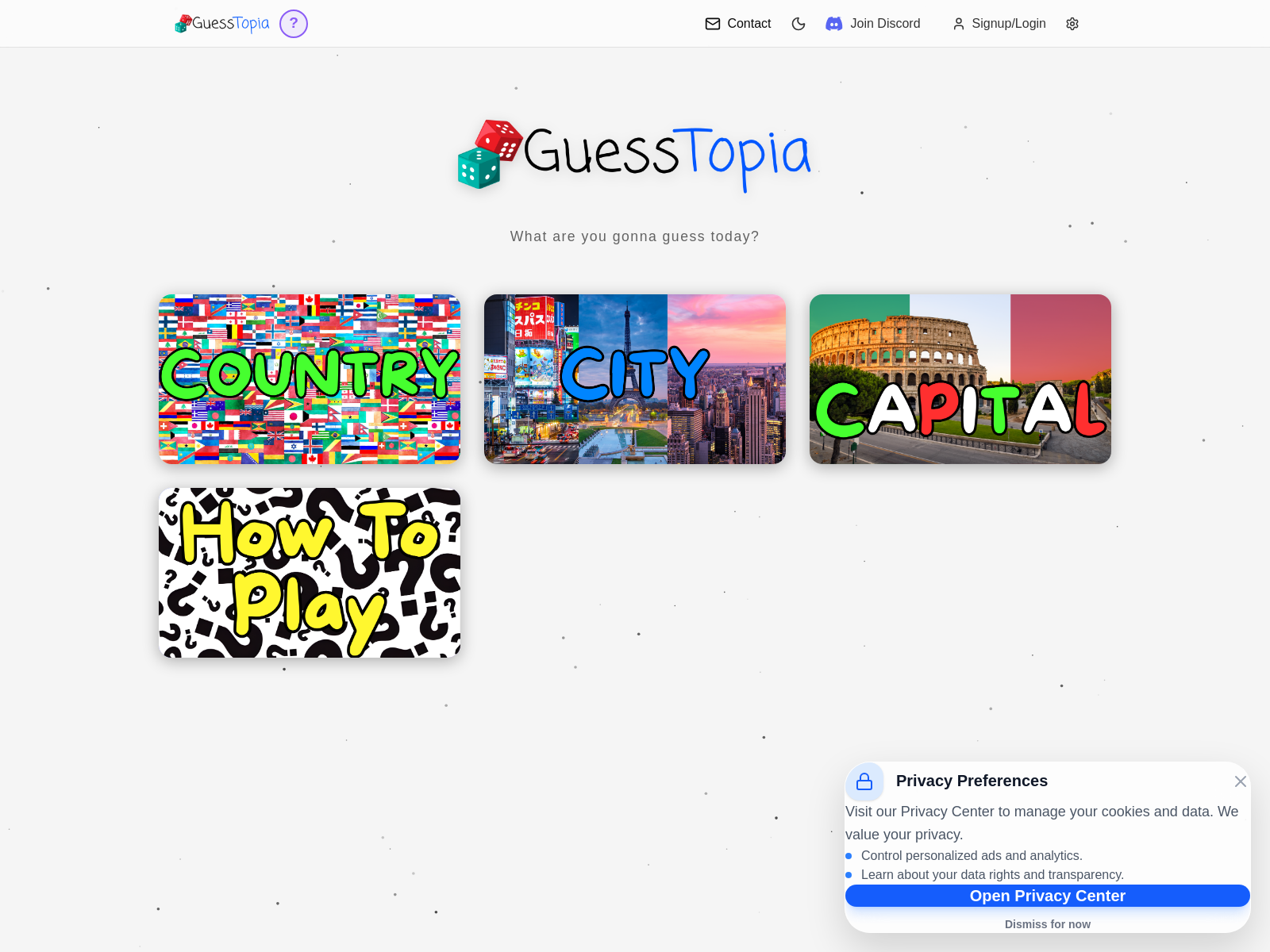
CongressWatch
CongressWatch是一款整合美国国会公开数据的可视化分析网站,提供投票记录、股票交易等异常评分功能。
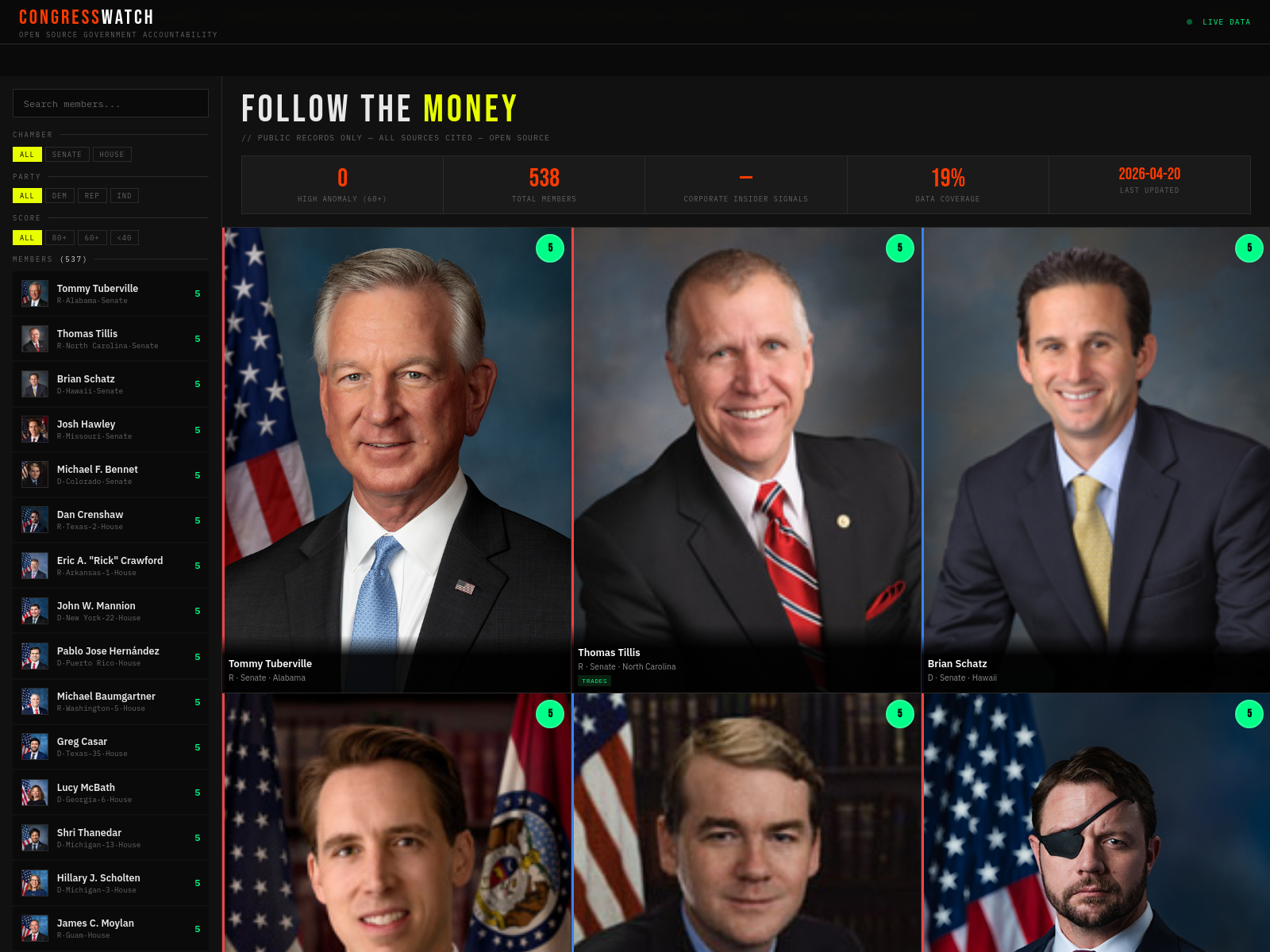
shadcnpreset
shadcnpreset是一个由社区投票驱动的shadcn UI预设库,支持关键词、风格或氛围浏览与预览,帮助开发者发现热门UI组合。
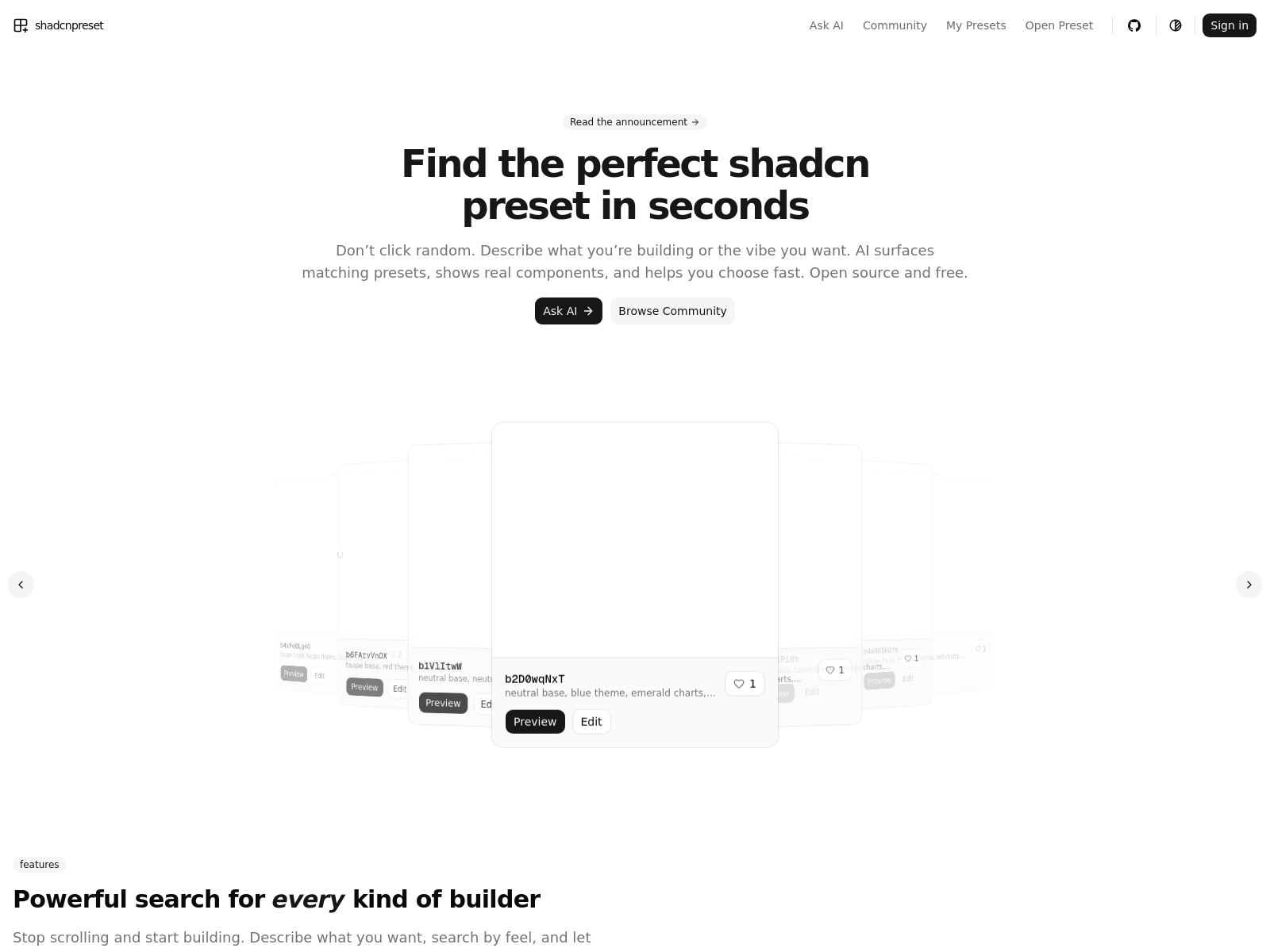
Dishcord
Dishcord是一款基于聊天布局的在线烹饪应用,用于存储和分享食谱,支持评论、点赞和收藏。
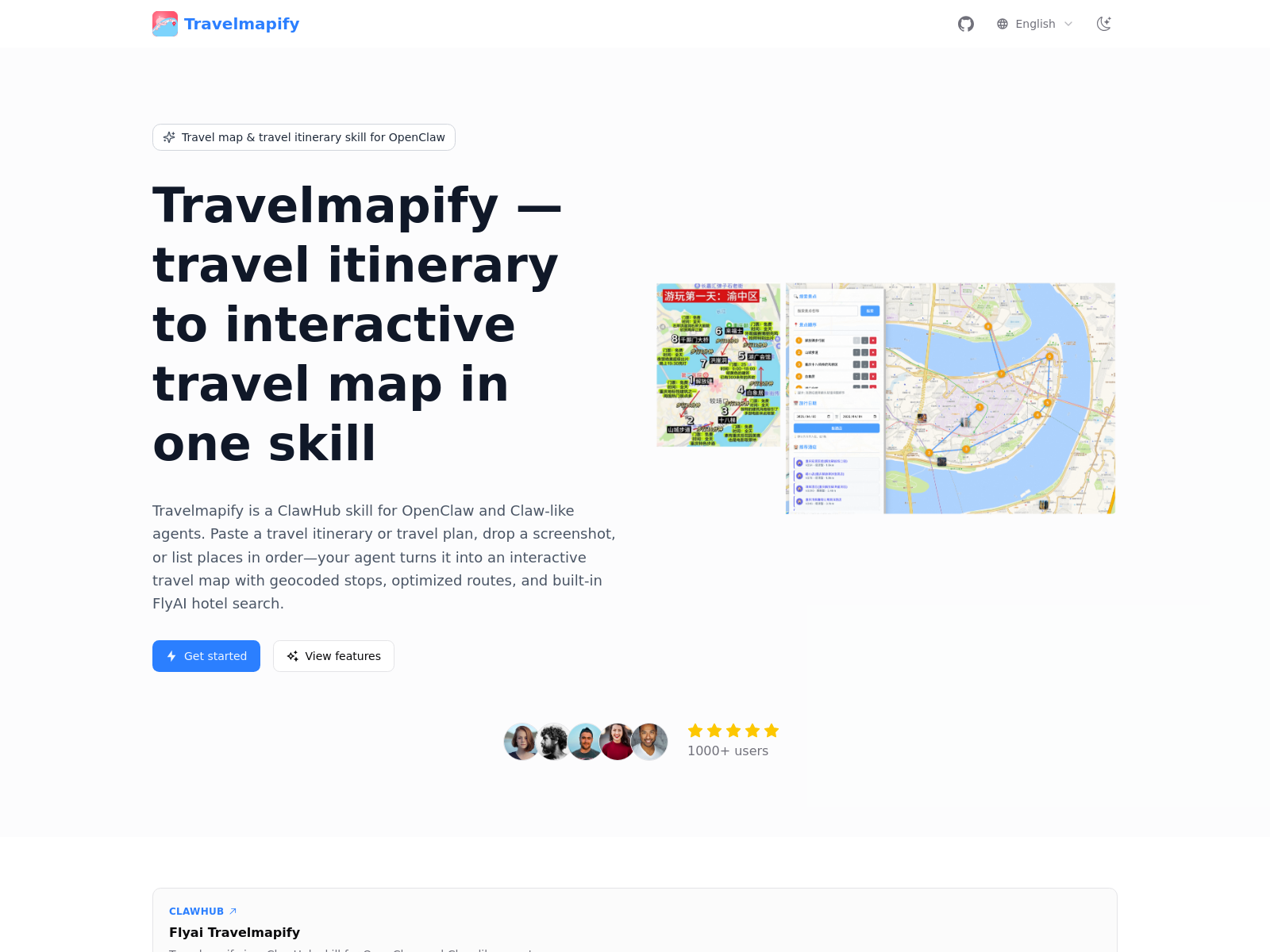
Travelmapify
Travelmapify是一款可一键复制小红书旅行计划地图的AI工具,支持生成行程规划,提升旅行准备效率。
✍️ 说明
日报相关信息:
网站:https://www.nomoyu.com/
RSS:https://www.nomoyu.com/rss/rss.xml
微信公众号:明航的AI副业
欢迎一起沟通交流
链接详见网站