2026-04-21. Nomoyu Daily pour les développeurs indies (édition 339)
📰 Actualités
L’IA fermée est en train de voler votre mine d’or de données
Quand des clients utilisent des modèles fermés prêts à l’emploi, le plus triste est qu’ils n’exploitent pas les données qu’ils ont accumulées pendant des années, parfois pendant des décennies.
Lorsque Guiam, le scientifique en chef de Mistral, a prononcé cette phrase dans le dernier entretien de Lin Space, le studio est resté silencieux quelques secondes.
Dehors, les rues de Paris continuaient de circuler. À l’écran défilaient les derniers nombres de paramètres et scores de benchmark des grands modèles. Nous avons pris l’habitude de comparer ces chiffres, d’ouvrir un navigateur, d’appeler une API, de poser une question et d’attendre une réponse.
Mais peu de gens regardent les fichiers endormis sur leurs propres serveurs.
Les conversations clients enregistrées depuis le premier jour de l’entreprise. Les documents techniques écrits par plusieurs générations d’ingénieurs. Les journaux laissés par d’innombrables itérations produit. Les expériences et leçons que seule une longue pratique d’un secteur permet d’obtenir.
Tout cela existe sous forme d’octets, dans un coin de disque dur. Une partie est déjà couverte de poussière numérique.
Ces données n’apparaîtront pas sur l’internet public.
Elles ne seront pas dans Common Crawl, ni dans Wikipédia, ni dans les jeux d’entraînement d’un grand modèle généraliste.
Elles n’appartiennent qu’à vous.
Elles racontent ce que vos clients aiment ou détestent, où ils hésitent et à quel moment ils achètent. Elles montrent où votre produit casse, où il peut être amélioré, et quelles règles tacites personne n’énonce publiquement dans votre secteur.
Quand vous envoyez toutes vos questions à un modèle généraliste, ces données continuent de dormir.
La réponse que vous recevez ne diffère pas de celle que votre concurrent recevra.
Même question. Même API. Même résultat.
L’équipe de Mistral a vu trop de clients dans ce cas. Ils arrivent avec des problèmes métier et expliquent que les modèles généralistes fonctionnent mal dans leur domaine. Puis les ingénieurs de Mistral prennent leurs données et affinent un petit modèle de 3 milliards de paramètres.
Le résultat dépasse souvent les attentes.
Une entreprise présente depuis vingt ans dans la santé affine un modèle sur ses propres dossiers médicaux et dépasse les grands modèles généralistes en précision diagnostique.
Un constructeur automobile entraîne un modèle sur ses données de ligne de production et améliore fortement la détection des défauts.
Une institution financière entraîne un modèle sur ses historiques de transactions et accélère l’évaluation du risque de plusieurs dizaines de fois.
Ces modèles n’ont même pas un centième de la taille de GPT-4.
Ils n’ont pas besoin de comprendre les sonnets de Shakespeare, de résoudre des mathématiques avancées ou d’écrire du code généraliste. Ils doivent faire une seule chose : comprendre votre métier.
Ils tournent sur vos serveurs ou dans votre cloud privé. Les données ne quittent pas l’entreprise et ne passent par aucun serveur tiers.
Vous n’avez plus à craindre une fuite de données, une hausse soudaine des prix d’API ou la fermeture brutale d’un service dont vous dépendez.
À la GTC, Mistral a lancé Forge. La plateforme met entre les mains des clients les outils internes que Mistral utilise pour entraîner ses modèles.
Les mêmes pipelines de données, le même code d’entraînement, les mêmes outils de fine-tuning. Ce que les scientifiques de Mistral utilisent chaque jour devient accessible à n’importe quelle entreprise.
Leurs ingénieurs vont chez les clients et travaillent avec les équipes. Ils nettoient les données, annotent les exemples, déboguent les modèles et résolvent les vrais problèmes métier.
Parfois, il s’agit d’apprendre au modèle le vocabulaire d’un secteur. Parfois, de l’adapter à un environnement acoustique précis. Parfois, de prendre en charge une langue minoritaire parlée par quelques millions de personnes.
Ce sont des choses qu’un grand modèle généraliste ne fera jamais vraiment bien.
Car un modèle généraliste doit servir le monde entier. Il ne peut que moyenner et donner une réponse acceptable dans la majorité des cas.
Il ne modifiera jamais ses poids pour une seule entreprise.
Le nouveau modèle Voxal TTS de Mistral ne compte lui aussi que 3 milliards de paramètres. Il prend en charge neuf langues, infère plus vite que la plupart des modèles comparables et coûte beaucoup moins cher.
Ils n’ont pas utilisé un gigantesque modèle généraliste pour générer de la voix. Ils ont construit un petit modèle spécialisé qui ne fait que cela.
Comme leur modèle de reconnaissance vocale. Comme leur modèle OCR.
Beaucoup parlent de grands modèles totalement multimodaux et d’un modèle unique capable de tout faire. Mistral prend le chemin inverse.
Ils pensent que, pour la plupart des problèmes concrets, un modèle petit et spécialisé est meilleur qu’un modèle immense et généraliste. Et beaucoup moins cher.
L’entretien a abordé de nombreux détails techniques : flow matching autorégressif, codecs audio neuronaux, modélisation de longs contextes.
Mais le point le plus marquant reste ce que Guiam a répété.
Les données.
Vos propres données.
Beaucoup d’entreprises dépensent des millions, des dizaines de millions, parfois plus, pour acheter des API fermées. Elles refusent pourtant d’investir une fraction de cette somme pour exploiter ce qu’elles possèdent déjà.
Elles enferment leur actif le plus précieux dans des disques durs, puis louent l’actif de quelqu’un d’autre.
Le jour où toutes les entreprises utiliseront le même grand modèle généraliste, d’où viendra l’avantage concurrentiel ?
Pas de la capacité à appeler la même API un peu mieux.
Il viendra de ceux qui possèdent des données que les autres n’ont pas.
De ceux qui transforment leurs données en leurs propres modèles.
De ceux qui font entrer des décennies d’expérience et de savoir-faire dans le monde numérique.
Les lumières du studio se sont éteintes. L’entretien était terminé.
Dehors, la nuit était tombée sur Paris. Dans toute la ville, des serveurs traitaient d’innombrables flux de données.
Certaines de ces données attendent encore d’être réveillées.

🖥️ Logiciels
Echo Japanese
Echo Japanese est une application d’apprentissage du vocabulaire japonais à partir d’anime, pensée pour les utilisateurs qui aiment l’animation japonaise et possèdent déjà quelques bases.
Knowledge Raven
Knowledge Raven est un outil de gestion des connaissances basé sur le protocole MCP, avec recherche intelligente de documents entre plateformes IA, import de fichiers et recherche collaborative multi-modèles.
Tubbr
Tubbr aide les créateurs YouTube et TikTok à générer scripts, images IA et vidéos à partir de mots-clés, pour produire du contenu de façon automatisée et peu coûteuse.
Prompt Vault
Prompt Vault est un gestionnaire de prompts sans backend, construit avec Astro et IndexedDB, avec stockage local, mode hors ligne et protection de la vie privée.
YNTA
YNTA est un logiciel de gestion d’entraînement à distance pour coachs personnels, avec connexion en temps réel par QR code, plans générés par IA et notes vocales.
markd-essay-ai
markd-essay-ai fournit correction et feedback IA pour les dissertations A-level au Royaume-Uni, avec prise en charge des programmes, génération de sujets blancs et correction automatique.
StackMap
StackMap est un outil CLI open source qui génère des schémas d’architecture modifiables localement depuis Terraform, CloudFormation, SAM ou des comptes AWS actifs, avec scan multi-comptes et visualisation interactive.
AI Subtitle Studio
AI Subtitle Studio est un éditeur vidéo de sous-titres IA dans le navigateur. Il analyse le ton, applique automatiquement des styles mot par mot et propose amélioration en un clic et édition riche.
🌐 Sites web
GuessTopia
GuessTopia est un jeu quotidien de géographie créé par un développeur indépendant. Il faut déduire un pays ou une capitale à partir d’indices comme le climat, la langue ou la population.
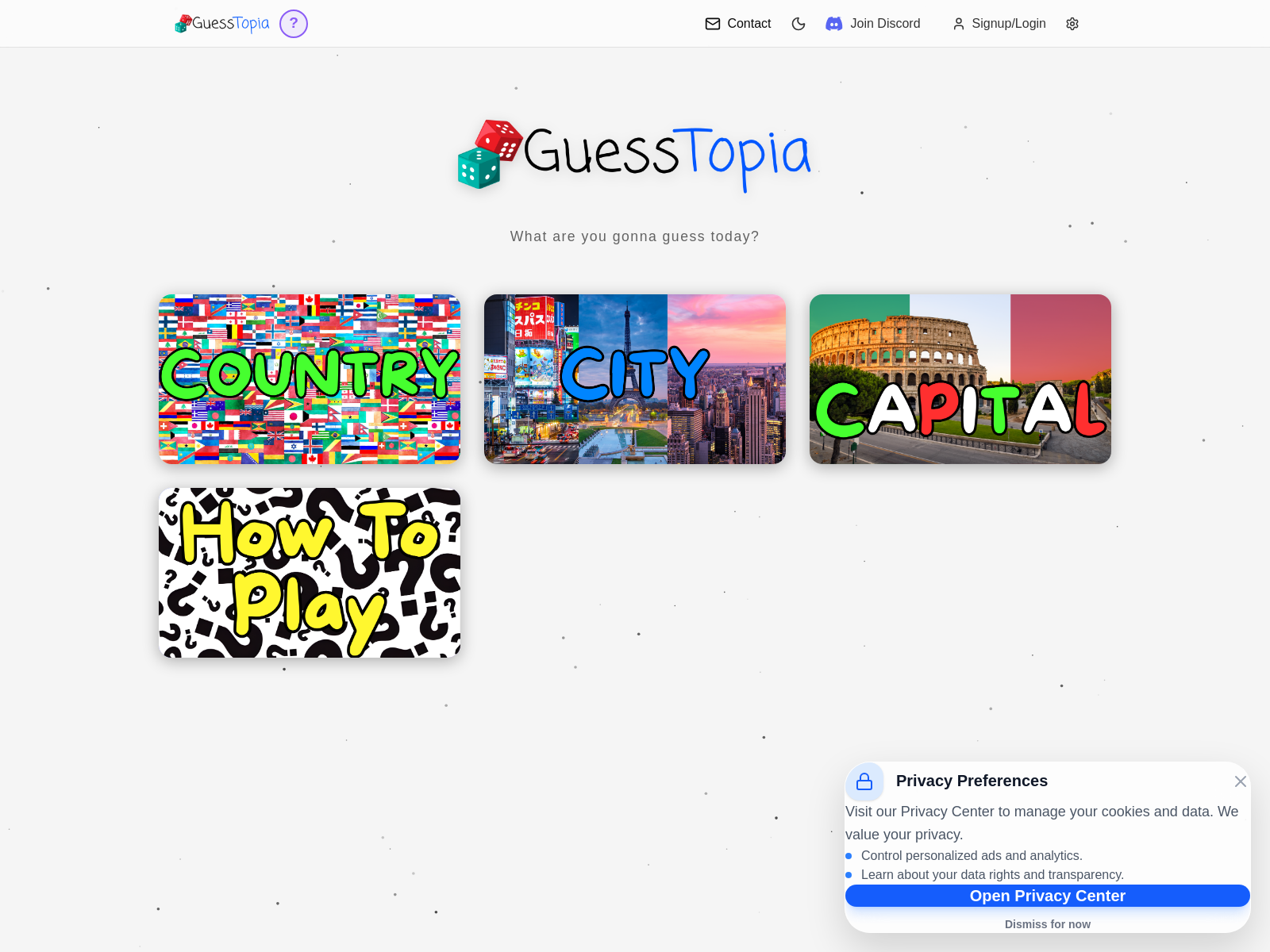
CongressWatch
CongressWatch est un site de visualisation de données publiques du Congrès américain, avec des scores d’anomalie pour les votes, transactions boursières et autres signaux.
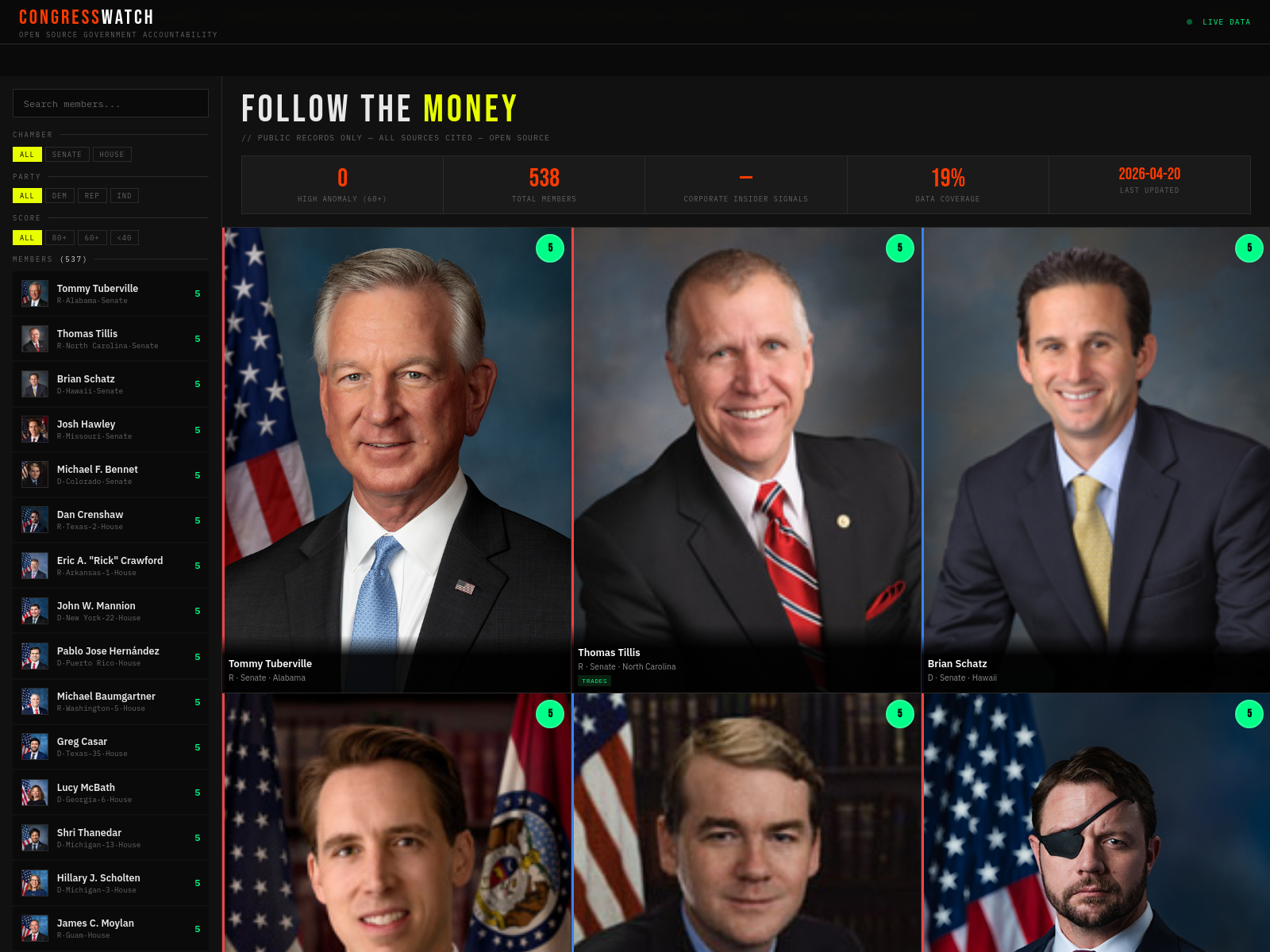
shadcnpreset
shadcnpreset est une bibliothèque de presets shadcn UI portée par le vote communautaire. Elle permet de parcourir et prévisualiser des combinaisons UI par mot-clé, style ou ambiance.
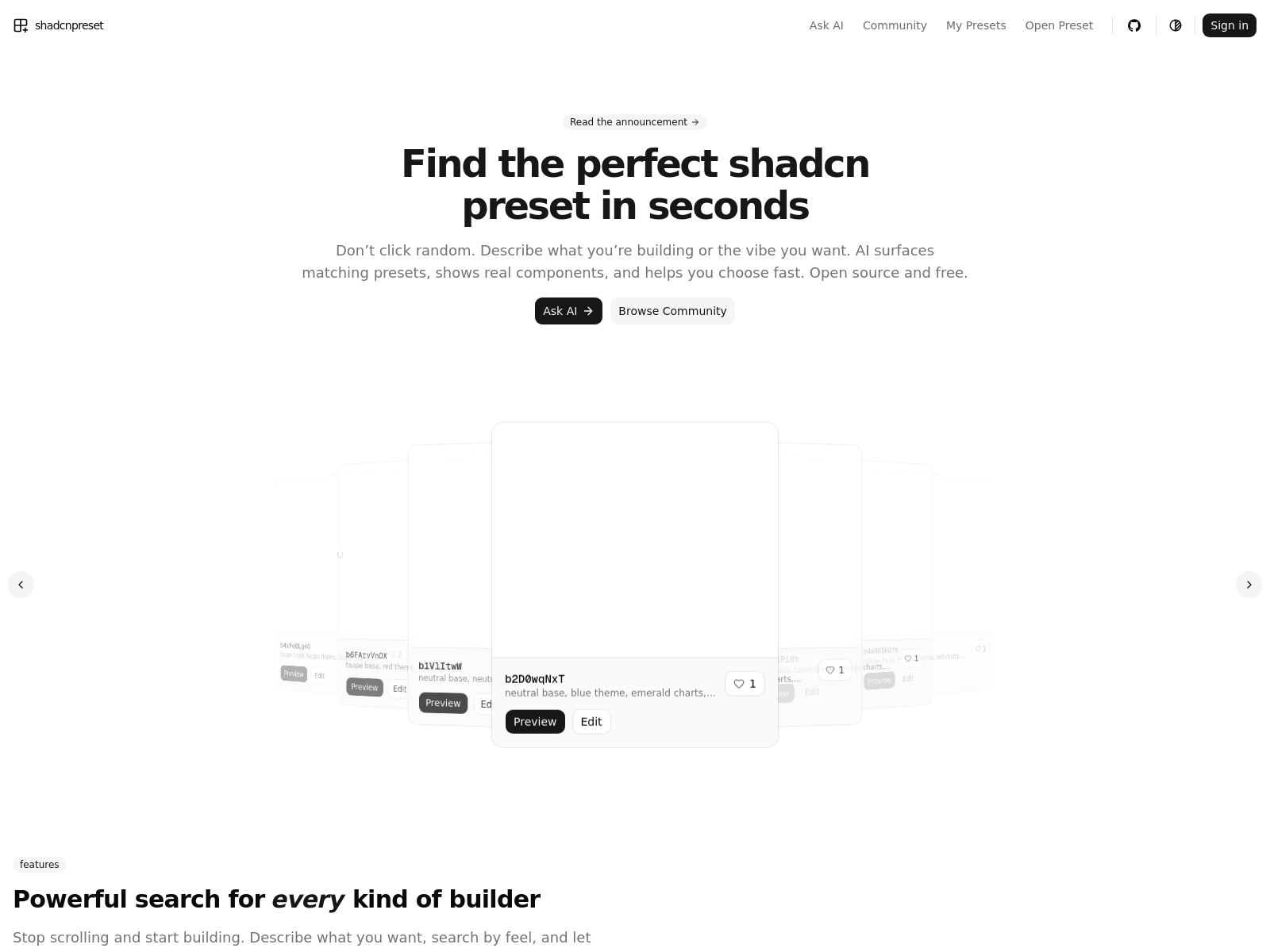
Dishcord
Dishcord est une application de cuisine en ligne avec une interface de discussion pour stocker et partager des recettes, avec commentaires, likes et favoris.
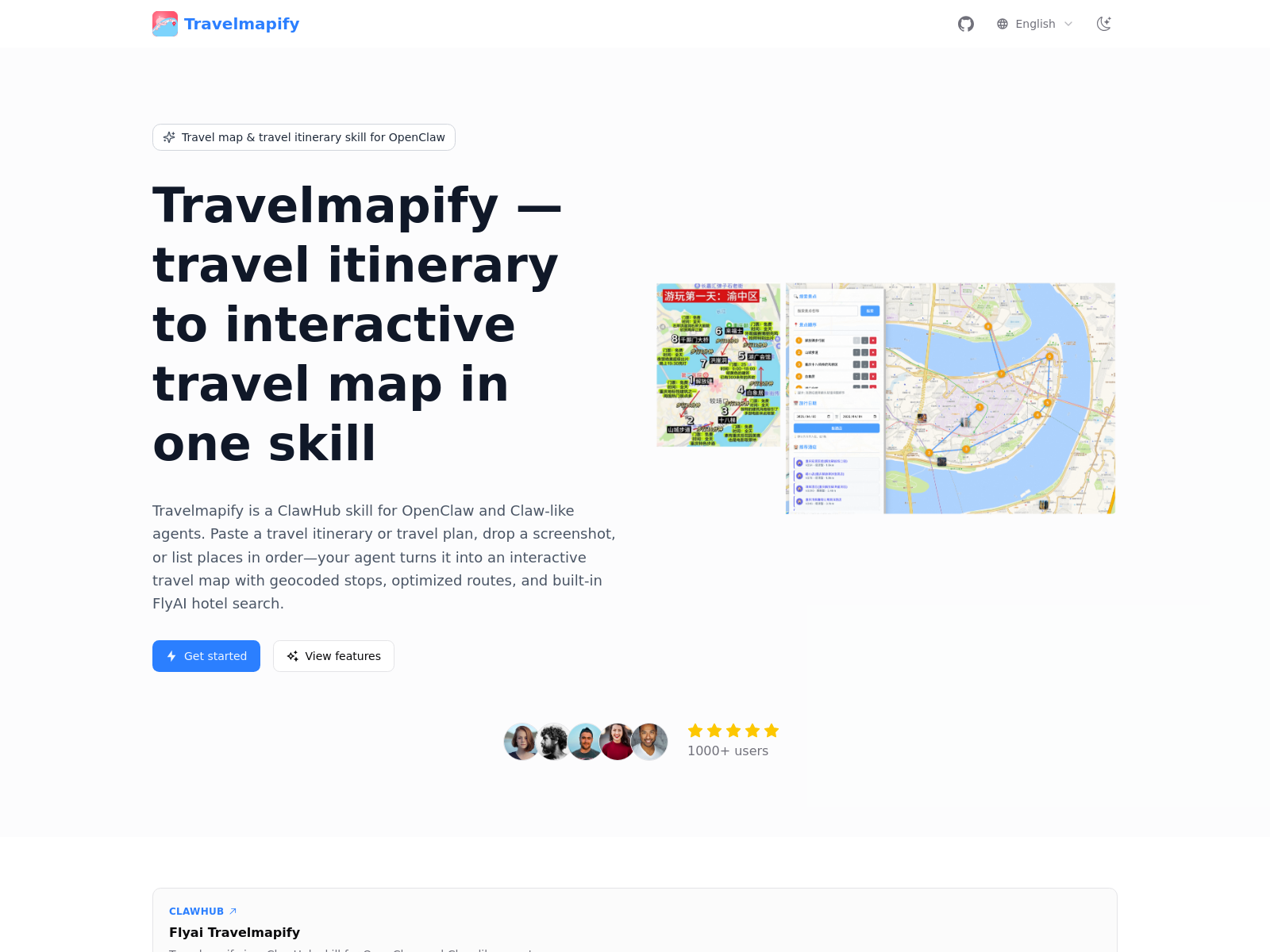
Travelmapify
Travelmapify est un outil IA capable de copier en un clic des cartes de voyage Xiaohongshu et de générer des itinéraires pour préparer ses voyages plus efficacement.
✍️ Notes
Informations du projet quotidien :
Site web : https://www.nomoyu.com/
RSS : https://www.nomoyu.com/rss/rss.xml
Compte officiel WeChat : 明航的AI副业
N’hésitez pas à échanger et à prendre contact
Tous les liens sont disponibles sur le site.