2026-04-21. インディー開発者のための Nomoyu Daily(第339号)
📰 ニュース
クローズドAIがあなたのデータ金鉱を奪っている
顧客が既製のクローズドモデルを使うとき、もっとも悲しいのは、何年も、時には何十年も蓄積してきた自社データを活用していないことだ。
MistralのチーフサイエンティストであるGuiamが、最新のLin Spaceインタビューでそう語った瞬間、スタジオは数秒間静まり返った。
窓の外ではパリの街がいつも通り流れ、画面には各社の大規模モデルの最新パラメータ数やベンチマークスコアが流れていた。人々はその数字を比べ、ブラウザを開き、APIを呼び、質問を入力して答えを待つことに慣れてしまった。
けれど、自分たちのサーバーに眠っているファイルを見下ろす人は少ない。
会社設立初日から記録されてきた顧客との会話。何世代ものエンジニアが残した技術文書。無数の製品改善で蓄積されたログ。その業界で長く揉まれなければ得られない経験と教訓。
それらはハードディスクの片隅にバイトとして存在している。すでにデジタルの埃をかぶっているものもある。
このデータは公開インターネットには出てこない。
Common Crawlにも、Wikipediaにも、どの汎用大規模モデルの学習データにも入っていない。
それはあなたたちだけのものだ。
顧客が何を好み、何を嫌い、どの段階で迷い、どの瞬間に購入するのかが記録されている。製品のどこが壊れやすく、どこを改善できるのかも記録されている。公の場では誰も語らない業界の暗黙知と常識も入っている。
すべての質問を汎用モデルに投げるとき、このデータは眠ったままだ。
あなたが得る答えは、競合が得る答えと変わらない。
同じ質問。同じAPI。同じ結果。
Mistralのチームは、こうした顧客を数多く見てきた。彼らは自分たちの課題を持ってMistralを訪れ、汎用モデルが自社領域ではうまく動かないと言う。そこでMistralのエンジニアは彼らのデータを受け取り、30億パラメータの小さなモデルをファインチューニングする。
結果はしばしば期待を超える。
医療業界で20年積み上げた企業が、自社の診療データでモデルを微調整し、診断精度で汎用大規模モデルを上回る。
自動車メーカーが生産ラインのデータでモデルを訓練し、欠陥検出の精度を大きく高める。
金融機関が取引履歴でモデルを学習させ、リスク評価の速度を何十倍にも上げる。
これらのモデルの規模は、GPT-4の1パーセントにも満たない。
シェイクスピアのソネットを理解する必要も、高等数学を解く必要も、汎用コードを書く必要もない。必要なのは一つだけ。あなたのビジネスを理解することだ。
モデルは自社サーバーやプライベートクラウドで動く。データは会社の外に出ず、第三者のサーバーを通らない。
データ漏えい、突然のAPI値上げ、ある朝起きたら依存していたサービスが停止していた、という不安から解放される。
MistralはGTCでForgeプラットフォームを発表した。彼らが社内でモデル訓練に使っているツールを、そのまま顧客に渡すものだ。
同じデータ処理パイプライン、同じ学習コード、同じファインチューニングツール。Mistralの科学者が日々使っているものを、どの企業でも使えるようにした。
エンジニアは顧客企業に入り、顧客チームと一緒に働く。データを整理し、サンプルにラベルを付け、モデルをデバッグし、実際の業務課題を解く。
ある時は、特定業界の専門用語をモデルに理解させるため。ある時は、特定の音響環境に適応させるため。ある時は、数百万人しか使わない小規模言語をサポートするため。
こうしたことは、汎用大規模モデルが永遠に得意になれない領域だ。
汎用モデルは世界中の全員に向けて作られる。平均を取り、多くの状況で使える答えを返すしかない。
一社のためだけに重みを調整することはない。
今回Mistralが公開したVoxal TTSモデルも、30億パラメータしかない。9言語に対応し、市場の多くの同種モデルより推論が速く、コストは数分の一だ。
彼らは音声生成に巨大な汎用モデルを使わなかった。この一つの仕事だけをする小さな専門モデルを作った。
以前の音声認識モデルと同じだ。OCRモデルと同じだ。
多くの人は全モーダル大規模モデルや、一つのモデルですべてを解く未来を語っている。だがMistralは逆の道を歩いている。
ほとんどの具体的な問題では、小さく専門化されたモデルの方が、大きく汎用的なモデルより良い。しかも安い。
インタビューでは、自己回帰フローマッチング、ニューラル音声コーデック、長文コンテキストモデリングなど、多くの技術的な話も出た。
それでも最も印象に残ったのは、Guiamが繰り返した言葉だった。
データ。
あなた自身のデータ。
多くの企業は、クローズドAPIの利用に数百万、数千万、時にはそれ以上を費やす。その一方で、すでに持っているデータを掘り起こすためには、その十分の一すら使おうとしない。
最も価値ある資産をハードディスクに閉じ込めたまま、他人の資産を借りている。
いつかすべての企業が同じ汎用大規模モデルを使うようになったとき、本当の競争優位はどこから生まれるのか。
同じAPIをより上手に呼ぶことからではない。
他社が持たないデータを持つことからだ。
自社データを自社モデルに変えることからだ。
何十年も積み上げてきた経験と知恵を、デジタルの世界に沈殿させることからだ。
スタジオの照明が落ちた。インタビューは終わった。
外はもう夜だった。パリの夜は明るく、街のあちこちでサーバーが無数のデータを処理している。
その中には、まだ目覚めるのを待っているデータがある。

🖥️ ソフトウェア
Echo Japanese
Echo Japaneseは、アニメを通じて日本語の単語を学ぶアプリで、日本のアニメに関心があり、ある程度の日本語基礎があるユーザーに向いている。
Knowledge Raven
Knowledge RavenはMCPプロトコルに基づくナレッジ管理ツールで、AIプラットフォーム横断のドキュメント検索、ファイルアップロード、複数モデルによる共同検索に対応している。
Tubbr
TubbrはYouTubeやTikTokクリエイター向けのAIツールで、キーワードからスクリプト、AI画像、動画を生成し、低コストな自動コンテンツ制作を支援する。
Prompt Vault
Prompt VaultはAstroとIndexedDBで作られたバックエンド不要のプロンプト管理ツールで、ローカル保存、オフライン利用、プライバシー保護を備えている。
YNTA
YNTAはパーソナルトレーナー向けの遠隔トレーニング管理ソフトで、QRコードによるリアルタイム接続、AIトレーニングプラン生成、音声記録に対応している。
markd-essay-ai
markd-essay-aiは英国A-level学生向けに、複数科目のエッセイをAIで採点しフィードバックするツールで、試験範囲対応、模擬問題生成、自動採点を備える。
StackMap
StackMapは、Terraform、CloudFormation、SAM、または実際のAWSアカウントからローカル編集可能なアーキテクチャ図を生成するオープンソースCLIツールで、複数アカウントのスキャンとインタラクティブな可視化に対応している。
AI Subtitle Studio
AI Subtitle Studioはブラウザで動くAI字幕動画エディタで、語調を分析して単語ごとに異なるスタイルを適用し、ワンクリック補正と単語単位のリッチテキスト編集に対応している。
🌐 Web サイト
GuessTopia
GuessTopiaはインディー開発者が作った毎日の地理パズルゲームで、気候、言語、人口などの手がかりから国や首都を推理する。
CongressWatch
CongressWatchは米国議会の公開データを統合する可視化分析サイトで、投票記録や株式取引などの異常スコアを提供する。
shadcnpreset
shadcnpresetはコミュニティ投票で運営されるshadcn UIプリセット集で、キーワード、スタイル、雰囲気から人気のUI組み合わせを閲覧・プレビューできる。
Dishcord
Dishcordはチャット型レイアウトのオンライン料理アプリで、レシピの保存と共有、コメント、いいね、お気に入りに対応している。
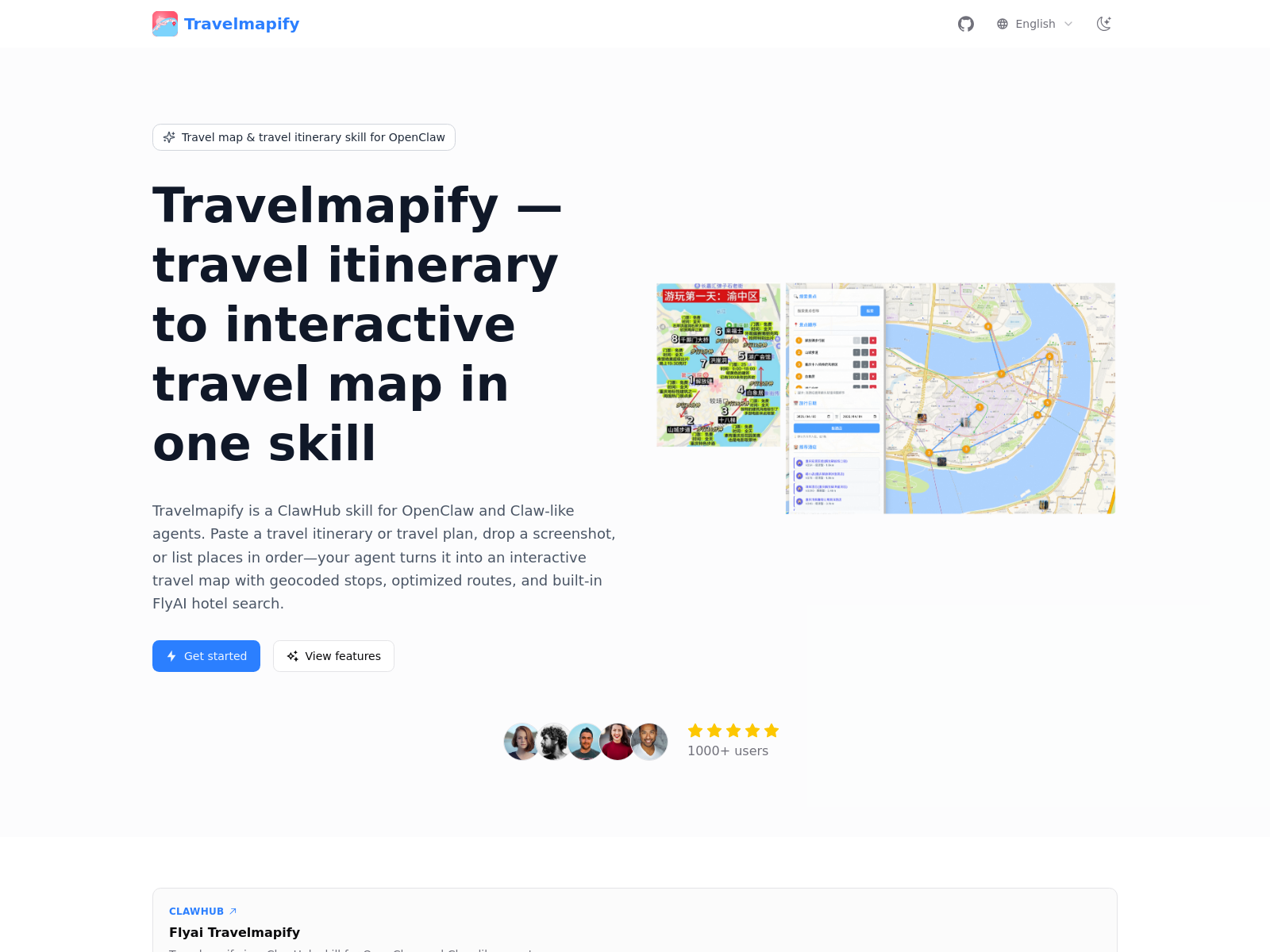
Travelmapify
Travelmapifyは、小紅書の旅行計画マップをワンクリックでコピーし、旅程を生成できるAIツールで、旅行準備を効率化する。
✍️ 補足
日刊プロジェクト情報:
Web サイト:https://www.nomoyu.com/
RSS:https://www.nomoyu.com/rss/rss.xml
WeChat 公式アカウント:明航的AI副业
気軽に交流してください
すべてのリンクはWebサイトで確認できます。